#38 - Don't refresh your fraud model until you read this
There’s nothing more frustrating than watching your fraud model deteriorate with time.
There you are, sitting on your hands while performance is decaying, fraudsters are eating your lunch, and false positive numbers are climbing each day.
“If only I could retrain the model with fresh data and release a new version,” you think to yourself, “that would solve all my problems.”
But if you ever went through this exercise, you know that things are more complex than they seem.
Your new model won’t just have better performance. Its entire score distribution will be different.
Here’s an example from Stripe Radar’s documentation that shows the difference in score distribution between models with different performance (orange = good, pink = fraud):
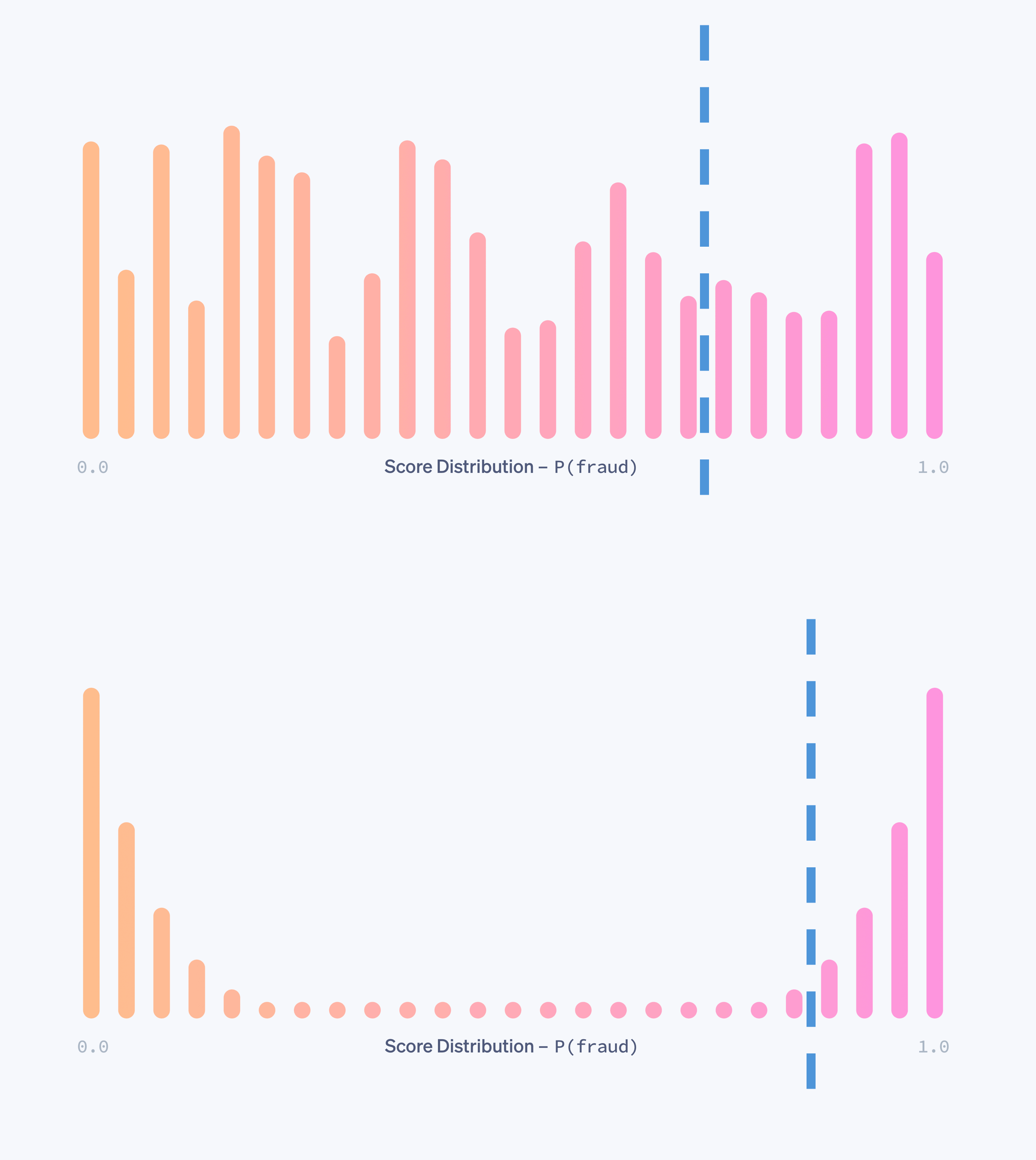
As can be seen in the example above, it might be that the new model catches more fraud for the same False Positive Rate, but it requires a change to the threshold.
Now I need to go through my endless list of rules and update them all.
Not fun.
Let’s solve it.
Why do score distributions change?
First, let’s understand why thresholds even change when we retrain the same model over new data.
Think about it like this: our model is a teacher assigned to score student essays. But it has no scoring guide, just the ability to compare between the essays.
If they grade 100 essays, some would get really good grades (>95) because they are the best, and some would get poor (<30) grades because they are quite bad.
Now, imagine the same teacher receiving another 200 essays and they are requested to regrade all 300 essays.
It’s likely that with more examples the teacher’s view on what is poor and what is great would change, and so would the grades.
The same goes for fraud models. By just adding more data, we essentially influence the scores and their distribution.
What makes it such a headache to fraud teams
You must be thinking now: “that can’t be that bad. You just change the model threshold rule from X to Y.”
Simple, right?
Well, in reality, we tend to use different thresholds for different needs:
Risk segments: different risk profiles will have different thresholds
B2B flows: individual merchants and/or partners will have different thresholds
Action flows: we’ll use a different threshold for automatic resolution versus manual investigation
And these are just examples. There can be many more reasons for us using different scores from the same model.
But wait, it gets worse!
One of the ways we can implement scores is conditions within behavioral fraud rules. I gave such an example in the past:

See the issue? I’m using the same risk score three times within a single rule, luckily with only two different thresholds. But you get the idea - I can have hundreds of thresholds hiding inside different rules.
But wait, it gets even worse!
Even if I manage to hunt down all the score appearances and change the thresholds to the new and correct ones, I still didn’t solve the main problem:
Validation.
I still need to test all the changes against current performance and make sure I didn’t create a negative impact within all of this complexity.
This can take days.
Are you convinced yet that refreshing models is a major headache? No? Still need more?
Here’s the kicker:
Ideally, from a pure data science perspective, we want our models to be retrained frequently and automatically.
Exactly for the reason for which we started going down this rabbit hole - avoiding performance degradation.
But now we understand that in reality, we’re creating a risk by introducing a change to the system, and not only an opportunity to gain a performance boost.
The more frequent the model refreshes are, the more I need to invest in re-calibrating and re-validating the thresholds.
And the more infrequent model refreshes are, the more our base model performance degrades.
A classic Catch-22.
Normalizing insanity
When I was running Fraugster, we encountered exactly this tension. But for us it was even worse as we were running three different algorithms in production.
Switching between models, not even refreshing them, presented a risk to our clients.
Here’s how we solved it: we introduced a new algorithm that sat on top of all our fraud scores. Its task? Normalizing score distributions across all models and all versions.
This way, we could introduce changes “under the hood”–refreshing models, switching algorithms–without the end user needing to do anything.
Score normalization is a known technique in Machine Learning, but there are multiple algorithms that address it.
You want to choose an algorithm that normalizes by quantiles, as the score distribution of fraud is not a standard bell-curve or even a predictable one (as we saw in the first image above).
The question is which quantiles you’re trying to normalize.
After a few experiments, we found out that what worked best is Decline Rate.
Meaning, our scores were normalized in a way that the same threshold (95 for example) would always decline the same population size (0.5% for example).
This way, our decline rates stayed the same when we made model changes, while catching more fraud.
You would think you’d want to set it for fraud rates. So each threshold would always catch the same amount of fraud.
The issue is that it can cause unwanted changes to acceptance rates and these always require much more overhead in communications.
The bottom line
Working towards a model refresh?
Pre-identify all the places where a threshold is being used
Make sure to test all changes before rolling out a new model version fully
Working towards frequent/automated model refreshes?
Start with a simple score normalization model
Only increase refresh pace once your normalization solution is validated to avoid introducing breaking changes
Have you also encountered the same dilemma? I’m curious to know if you took a different approach to solving it. Hit reply and let me know!
In the meantime, that’s all for this week.
See you next Saturday.
P.S. If you feel like you're running out of time and need some expert advice with getting your fraud strategy on track, here's how I can help you:
Free Discovery Call - Unsure where to start or have a specific need? Schedule a 15-min call with me to assess if and how I can be of value.
Schedule a Discovery Call Now »
Consultation Call - Need expert advice on fraud? Meet with me for a 1-hour consultation call to gain the clarity you need. Guaranteed.
Book a Consultation Call Now »
Fraud Strategy Action Plan - Is your Fintech struggling with balancing fraud prevention and growth? Are you thinking about adding new fraud vendors or even offering your own fraud product? Sign up for this 2-week program to get your tailored, high-ROI fraud strategy action plan so that you know exactly what to do next.
Sign-up Now »
Enjoyed this and want to read more? Sign up to my newsletter to get fresh, practical insights weekly!